In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
The main differences between LinearSVC and SVC lie in the loss function used by default, and in the handling of intercept regularization between those two implementations.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
sklearn实现的 soft-margin linear Support Vector Machine 在 from sklearn.linear_model import SGDClassifier类中给出。 sklearn使用的是 one versus all (OVA) scheme,文档摘录如下
For each of the classes, a binary classifier is learned that discriminates between that and all other classes. At testing time, we compute the confidence score (i.e. the signed distances to the hyperplane) for each classifier and choose the class with the highest confidence.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
235 ms ± 39.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
94.6 ms ± 6.33 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
232 ms ± 16.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
79.5 ms ± 7.33 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
284 ms ± 38.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
99.1 ms ± 7.91 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
274 ms ± 34.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
58 ms ± 4.13 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
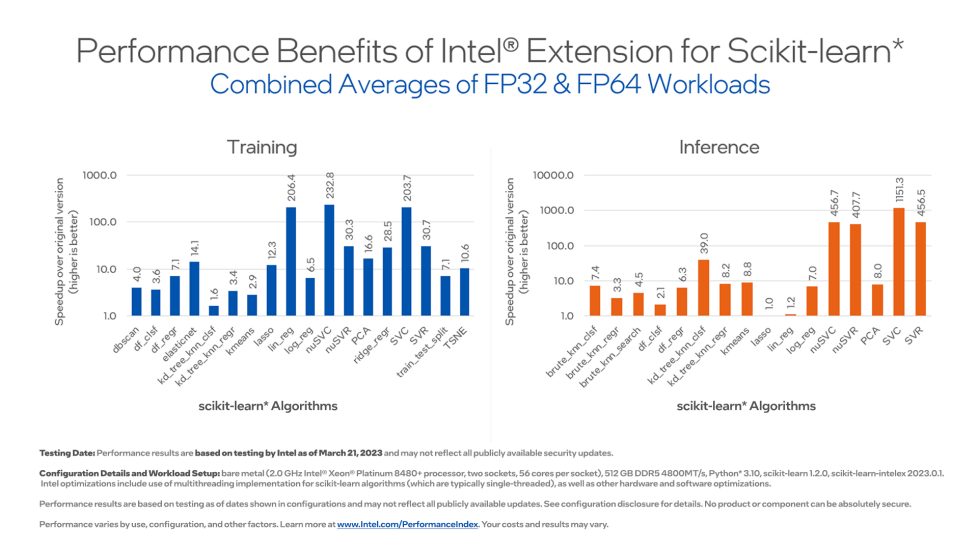
英特尔宣称 对SVC的加速可以达到203.7%,然而我们并没有看到这样的结果。 我们使用假设检验来看看英特尔的sklearn是不是显著地块?这里由于结果是相关的,而且不能假设是正态分布,所以使用 wilcoxon signed rank 检验。
from scipy.stats import wilcoxon
original_sklearn_time = [t.best for t in original_sklearn]intel_sklearn_time = [t.best for t in intel_sklearn]res_less = wilcoxon(intel_sklearn_time, original_sklearn_time, zero_method='zsplit',alternative='less'# 实验备则假设, intel_sklearn 用时更短 )if res_less.pvalue >0.05:print("Null hypothesis cannot be rejected, so I have to accept that intel_sklearn is not faster than original_sklearn. ")res_lessres_greater = wilcoxon(intel_sklearn_time, original_sklearn_time, zero_method='zsplit', alternative='greater'# 实验备则假设,intel_sklearn 用时更长 )res_less, res_greater
Sun 2024-11-17 01:36:45.594639
INFO Null hypothesis cannot be rejected, so I have to accept that intel_sklearn is not faster nucleus.py:53
than original_sklearn.
{kind=link}