Binary Hinge Loss. For SVM, \[
\min_{w, b} rac{1}{2} \lVert w Vert^2 + C \sum_{i=1}^N \left[ 1 - y_i(w \cdot x_i + b) ight]_+
\] we compute \[
C \sum_{i=1}^N \left[ 1 - y_i(w \cdot x_i + b) ight]_+
\]
Exported source
import torchimport torch.nn as nnfrom fastcore.allimport store_attr
Exported source
class BinaryHingeLoss(nn.Module):""" Binary Hinge Loss. For SVM, $$ \min_{w, b} \frac{1}{2} \lVert w \rVert^2 + C \sum_{i=1}^N \left[ 1 - y_i(w \cdot x_i + b) \right]_+ $$ we compute $$ C \sum_{i=1}^N \left[ 1 - y_i(w \cdot x_i + b) \right]_+ $$ """def__init__(self, C=1.0, squared =False, margin =1.0, ):super().__init__() store_attr() # 保存参数到实例变量中def forward(self, y_pred_logits:torch.Tensor, y_true:torch.Tensor)->torch.Tensor: functional_margin = y_true * y_pred_logits # 函数间隔 how_small_than_required_margin =self.margin - functional_margin xi = torch.clamp(how_small_than_required_margin, min=0) # 计算 xi 也就是 松弛变量ifself.squared: xi = xi **2returnself.C * xi.sum()
其中 squared 参数表示是否使用 squared hinge loss。 什么叫做 squared hinge loss 呢?我们做过理论作业,李航《统计学习方法》153页例题 7.3 提到了 (但是书上没有给出Reference) \[
\min_{w, b} \frac{1}{2} \lVert w \rVert^2 + C \sum_{i=1}^N \xi_i^2
\] 来取代 \[
\min_{w, b} \frac{1}{2} \lVert w \rVert^2 + C \sum_{i=1}^N \xi_i
\] 其实上面那个式子就是 squared hinge loss。
from overrides import overridefrom lightning.pytorch.utilities.types import EVAL_DATALOADERS, TRAIN_DATALOADERS, STEP_OUTPUT, OptimizerLRSchedulerimport torch.optim as optimimport lightning as L
Exported source
# lightning imports
Exported source
class HingeSupportVectorClassifier(L.LightningModule):def__init__(self, # model related input_dim, num_classes, # optimization related learning_rate=0.01, weight_decay=0.5, optimizer_type = optim.SGD, # loss related C: float=1, squared: bool=False, margin: float=1, strategy: Strategy ='crammer_singer',# experiment related experiment_index=0, ):super().__init__()self.save_hyperparameters() L.seed_everything(experiment_index)self.model = nn.Linear(input_dim, num_classes)self.loss_fn = MultiClassHingeLoss()self.example_input_array = torch.randn(1, input_dim)self.dummy_inputs =dict(input_ids=self.example_input_array) # for opendelta and huggingfaceself.automatic_optimization =True# 评价策略self.evaluation_steps_outputs =dict()@overridedef forward(self, image_tensor:torch.Tensor, *args, **kwargs)-> torch.Tensor:""" Returns: torch.Tensor: the predicted functional margin to each class's decision hyperplane """returnself.model(image_tensor)def predict_geometric_margin(self, image_tensor:torch.Tensor)->torch.Tensor: w_norm_each_line = torch.norm(self.model.weight, dim=1)return torch.clamp(self(image_tensor) / w_norm_each_line, min=0)def predict_class(self, image_tensor:torch.Tensor)->torch.Tensor:return torch.argmax(self(image_tensor), dim=1)def forward_loss(self, image_tensor: torch.Tensor, label_tensor:torch.Tensor)->torch.Tensor: logits =self(image_tensor)returnself.loss_fn(logits, label_tensor)@overridedef training_step(self, batch, batch_idx=None, *args, **kwargs)-> STEP_OUTPUT: loss =self.forward_loss(*batch)self.log("train_loss", loss, prog_bar=True)return loss
from namable_classify.infra import print_model_pretty
INFO ╭─────────────────────── Model Tree for HingeSupportVectorClassifier ────────────────────────╮ torch.py:72
│ root │
│ └── model (Linear) weight:[10, 784] bias:[10] │
╰────────────────────────────────────────────────────────────────────────────────────────────╯
tensor(1.4472, grad_fn=<MulBackward0>)
我们定义好了 loss 和 model(w与b的参数,以及决策超平面如何用于决策)。 现在我们要定义训练算法。
*Choose what optimizers and learning-rate schedulers to use in your optimization. Normally you’d need one. But in the case of GANs or similar you might have multiple. Optimization with multiple optimizers only works in the manual optimization mode.
Return: Any of these 6 options.
- **Single optimizer**.
- **List or Tuple** of optimizers.
- **Two lists** - The first list has multiple optimizers, and the second has multiple LR schedulers
(or multiple ``lr_scheduler_config``).
- **Dictionary**, with an ``"optimizer"`` key, and (optionally) a ``"lr_scheduler"``
key whose value is a single LR scheduler or ``lr_scheduler_config``.
- **None** - Fit will run without any optimizer.
The lr_scheduler_config is a dictionary which contains the scheduler and its associated configuration. The default configuration is shown below.
.. code-block:: python
lr_scheduler_config = {
# REQUIRED: The scheduler instance
"scheduler": lr_scheduler,
# The unit of the scheduler's step size, could also be 'step'.
# 'epoch' updates the scheduler on epoch end whereas 'step'
# updates it after a optimizer update.
"interval": "epoch",
# How many epochs/steps should pass between calls to
# `scheduler.step()`. 1 corresponds to updating the learning
# rate after every epoch/step.
"frequency": 1,
# Metric to to monitor for schedulers like `ReduceLROnPlateau`
"monitor": "val_loss",
# If set to `True`, will enforce that the value specified 'monitor'
# is available when the scheduler is updated, thus stopping
# training if not found. If set to `False`, it will only produce a warning
"strict": True,
# If using the `LearningRateMonitor` callback to monitor the
# learning rate progress, this keyword can be used to specify
# a custom logged name
"name": None,
}
When there are schedulers in which the .step() method is conditioned on a value, such as the :class:torch.optim.lr_scheduler.ReduceLROnPlateau scheduler, Lightning requires that the lr_scheduler_config contains the keyword "monitor" set to the metric name that the scheduler should be conditioned on.
.. testcode::
# The ReduceLROnPlateau scheduler requires a monitor
def configure_optimizers(self):
optimizer = Adam(...)
return {
"optimizer": optimizer,
"lr_scheduler": {
"scheduler": ReduceLROnPlateau(optimizer, ...),
"monitor": "metric_to_track",
"frequency": "indicates how often the metric is updated",
# If "monitor" references validation metrics, then "frequency" should be set to a
# multiple of "trainer.check_val_every_n_epoch".
},
}
# In the case of two optimizers, only one using the ReduceLROnPlateau scheduler
def configure_optimizers(self):
optimizer1 = Adam(...)
optimizer2 = SGD(...)
scheduler1 = ReduceLROnPlateau(optimizer1, ...)
scheduler2 = LambdaLR(optimizer2, ...)
return (
{
"optimizer": optimizer1,
"lr_scheduler": {
"scheduler": scheduler1,
"monitor": "metric_to_track",
},
},
{"optimizer": optimizer2, "lr_scheduler": scheduler2},
)
Metrics can be made available to monitor by simply logging it using self.log('metric_to_track', metric_val) in your :class:~lightning.pytorch.core.LightningModule.
Note: Some things to know:
- Lightning calls ``.backward()`` and ``.step()`` automatically in case of automatic optimization.
- If a learning rate scheduler is specified in ``configure_optimizers()`` with key
``"interval"`` (default "epoch") in the scheduler configuration, Lightning will call
the scheduler's ``.step()`` method automatically in case of automatic optimization.
- If you use 16-bit precision (``precision=16``), Lightning will automatically handle the optimizer.
- If you use :class:`torch.optim.LBFGS`, Lightning handles the closure function automatically for you.
- If you use multiple optimizers, you will have to switch to 'manual optimization' mode and step them
yourself.
- If you need to control how often the optimizer steps, override the :meth:`optimizer_step` hook.*
*Operates on a single batch of data from the test set. In this step you’d normally generate examples or calculate anything of interest such as accuracy.
Args: batch: The output of your data iterable, normally a :class:~torch.utils.data.DataLoader. batch_idx: The index of this batch. dataloader_idx: The index of the dataloader that produced this batch. (only if multiple dataloaders used)
Return: - :class:~torch.Tensor - The loss tensor - dict - A dictionary. Can include any keys, but must include the key 'loss'. - None - Skip to the next batch.
.. code-block:: python
# if you have one test dataloader:
def test_step(self, batch, batch_idx): ...
# if you have multiple test dataloaders:
def test_step(self, batch, batch_idx, dataloader_idx=0): ...
Examples::
# CASE 1: A single test dataset
def test_step(self, batch, batch_idx):
x, y = batch
# implement your own
out = self(x)
loss = self.loss(out, y)
# log 6 example images
# or generated text... or whatever
sample_imgs = x[:6]
grid = torchvision.utils.make_grid(sample_imgs)
self.logger.experiment.add_image('example_images', grid, 0)
# calculate acc
labels_hat = torch.argmax(out, dim=1)
test_acc = torch.sum(y == labels_hat).item() / (len(y) * 1.0)
# log the outputs!
self.log_dict({'test_loss': loss, 'test_acc': test_acc})
If you pass in multiple test dataloaders, :meth:test_step will have an additional argument. We recommend setting the default value of 0 so that you can quickly switch between single and multiple dataloaders.
.. code-block:: python
# CASE 2: multiple test dataloaders
def test_step(self, batch, batch_idx, dataloader_idx=0):
# dataloader_idx tells you which dataset this is.
...
Note: If you don’t need to test you don’t need to implement this method.
Note: When the :meth:test_step is called, the model has been put in eval mode and PyTorch gradients have been disabled. At the end of the test epoch, the model goes back to training mode and gradients are enabled.*
Exported source
from namable_classify.infra import append_dict_list, ensure_arrayfrom typing import Anyimport numpy as np
*Operates on a single batch of data from the validation set. In this step you’d might generate examples or calculate anything of interest like accuracy.
Args: batch: The output of your data iterable, normally a :class:~torch.utils.data.DataLoader. batch_idx: The index of this batch. dataloader_idx: The index of the dataloader that produced this batch. (only if multiple dataloaders used)
Return: - :class:~torch.Tensor - The loss tensor - dict - A dictionary. Can include any keys, but must include the key 'loss'. - None - Skip to the next batch.
.. code-block:: python
# if you have one val dataloader:
def validation_step(self, batch, batch_idx): ...
# if you have multiple val dataloaders:
def validation_step(self, batch, batch_idx, dataloader_idx=0): ...
Examples::
# CASE 1: A single validation dataset
def validation_step(self, batch, batch_idx):
x, y = batch
# implement your own
out = self(x)
loss = self.loss(out, y)
# log 6 example images
# or generated text... or whatever
sample_imgs = x[:6]
grid = torchvision.utils.make_grid(sample_imgs)
self.logger.experiment.add_image('example_images', grid, 0)
# calculate acc
labels_hat = torch.argmax(out, dim=1)
val_acc = torch.sum(y == labels_hat).item() / (len(y) * 1.0)
# log the outputs!
self.log_dict({'val_loss': loss, 'val_acc': val_acc})
If you pass in multiple val dataloaders, :meth:validation_step will have an additional argument. We recommend setting the default value of 0 so that you can quickly switch between single and multiple dataloaders.
.. code-block:: python
# CASE 2: multiple validation dataloaders
def validation_step(self, batch, batch_idx, dataloader_idx=0):
# dataloader_idx tells you which dataset this is.
...
Note: If you don’t need to validate you don’t need to implement this method.
Note: When the :meth:validation_step is called, the model has been put in eval mode and PyTorch gradients have been disabled. At the end of validation, the model goes back to training mode and gradients are enabled.*
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/fabric/plugins/environments/slurm.py:204: The `srun` command is available on your system but is not used. HINT: If your intention is to run Lightning on SLURM, prepend your python command with `srun` like so: srun python /home/ye_canming/program_files/managers/conda/envs/y ...
Trainer already configured with model summary callbacks: [<class 'lightning.pytorch.callbacks.model_summary.ModelSummary'>]. Skipping setting a default `ModelSummary` callback.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/pytorch/loops/utilities.py:72: `max_epochs` was not set. Setting it to 1000 epochs. To train without an epoch limit, set `max_epochs=-1`.
INFO: LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]
Sat 2024-11-16 00:58:49.020341
INFO LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]cuda.py:61
INFO:
| Name | Type | Params | Mode | In sizes | Out sizes
-------------------------------------------------------------------------------
0 | model | Linear | 650 | train | [1, 64] | [1, 10]
1 | loss_fn | MultiClassHingeLoss | 0 | train | ? | ?
-------------------------------------------------------------------------------
650 Trainable params
0 Non-trainable params
650 Total params
0.003 Total estimated model params size (MB)
2 Modules in train mode
0 Modules in eval mode
Sat 2024-11-16 00:58:49.057947
INFO model_summary.py:104
| Name | Type | Params | Mode | In sizes | Out sizes
------------------------------------------------------------------------------- 0 | model | Linear | 650 | train | [1, 64] | [1, 10]1 | loss_fn | MultiClassHingeLoss | 0 | train | ? | ?
------------------------------------------------------------------------------- 650 Trainable params 0 Non-trainable params 650 Total params 0.003 Total estimated model params size (MB)2 Modules in train mode 0 Modules in eval mode
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py:298: The number of training batches (11) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
INFO: Metric val_acc1 improved. New best score: 0.514
INFO: Metric val_acc1 improved by 0.229 >= min_delta = 0.0. New best score: 0.743
Sat 2024-11-16 00:58:55.733727
INFO Metric val_acc1 improved by 0.229 >= min_delta = 0.0. New best score: 0.743early_stopping.py:273
INFO: Metric val_acc1 improved by 0.007 >= min_delta = 0.0. New best score: 0.750
Sat 2024-11-16 00:59:01.783794
INFO Metric val_acc1 improved by 0.007 >= min_delta = 0.0. New best score: 0.750early_stopping.py:273
INFO: Metric val_acc1 improved by 0.111 >= min_delta = 0.0. New best score: 0.861
Sat 2024-11-16 00:59:09.920693
INFO Metric val_acc1 improved by 0.111 >= min_delta = 0.0. New best score: 0.861early_stopping.py:273
INFO: Metric val_acc1 improved by 0.042 >= min_delta = 0.0. New best score: 0.903
Sat 2024-11-16 00:59:14.194501
INFO Metric val_acc1 improved by 0.042 >= min_delta = 0.0. New best score: 0.903early_stopping.py:273
INFO: Monitored metric val_acc1 did not improve in the last 5 records. Best score: 0.903. Signaling Trainer to stop.
Sat 2024-11-16 00:59:26.505406
INFO Monitored metric val_acc1 did not improve in the last 5 records. Best score: 0.903. early_stopping.py:273
Signaling Trainer to stop.
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/fabric/plugins/environments/slurm.py:204: The `srun` command is available on your system but is not used. HINT: If your intention is to run Lightning on SLURM, prepend your python command with `srun` like so: srun python /home/ye_canming/program_files/managers/conda/envs/y ...
INFO: LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]
Sat 2024-11-16 00:59:27.127571
INFO LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]cuda.py:61
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/fabric/plugins/environments/slurm.py:204: The `srun` command is available on your system but is not used. HINT: If your intention is to run Lightning on SLURM, prepend your python command with `srun` like so: srun python /home/ye_canming/program_files/managers/conda/envs/y ...
INFO: LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]
Sat 2024-11-16 00:59:28.313136
INFO LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]cuda.py:61
首先optimizer_type选择ASGD还是SGD,squared是hinge loss还是squared hinge loss,strategy使用crammer_singer还是one vs all, 这三个参数的选择自然是会影响到最终的结果,是重要的目标元参数或者冗余元参数。然而,剩下的learning_rate,weight_decay和C, margin我们可以发现,本质上只有前两个。C和learning_rate是一样的效果,而margin是一个函数间隔,也是可以任意选取的,不影响优化问题的最优解(当然会一定程度影响landscape)。
INFO: Trainer will use only 1 of 8 GPUs because it is running inside an interactive / notebook environment. You may try to set `Trainer(devices=8)` but please note that multi-GPU inside interactive / notebook environments is considered experimental and unstable. Your mileage may vary.
Sat 2024-11-16 00:52:49.928983
INFO Trainer will use only 1 of 8 GPUs because it is running inside an interactive / notebook rank_zero.py:63
environment. You may try to set `Trainer(devices=8)` but please note that multi-GPU inside
interactive / notebook environments is considered experimental and unstable. Your mileage
may vary.
INFO: GPU available: True (cuda), used: True
Sat 2024-11-16 00:52:49.953772
INFO GPU available: True(cuda), used: Truerank_zero.py:63
INFO: TPU available: False, using: 0 TPU cores
Sat 2024-11-16 00:52:49.958918
INFO TPU available: False, using: 0 TPU cores rank_zero.py:63
INFO: HPU available: False, using: 0 HPUs
Sat 2024-11-16 00:52:49.962648
INFO HPU available: False, using: 0 HPUs rank_zero.py:63
INFO LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]cuda.py:61
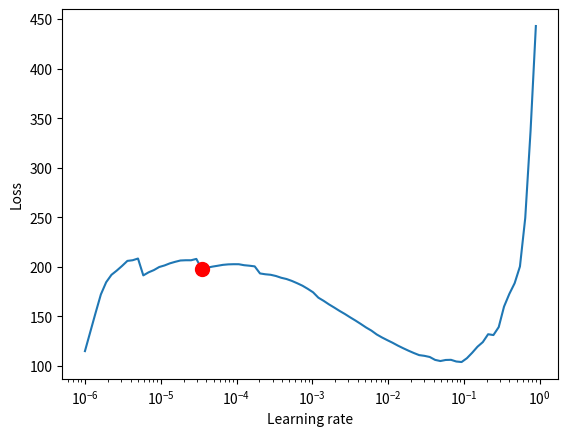
INFO: LR finder stopped early after 85 steps due to diverging loss.
Sat 2024-11-16 00:53:03.916698
INFO LR finder stopped early after 85 steps due to diverging loss. lr_finder.py:282
INFO: Learning rate set to 3.467368504525316e-05
Sat 2024-11-16 00:53:03.941939
INFO Learning rate set to 3.467368504525316e-05lr_finder.py:301
INFO: Restoring states from the checkpoint path at /home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/notebooks/coding_projects/P2_SVM/.lr_find_eeb25b7b-6568-46de-b7da-ccdf5af0b22b.ckpt
Sat 2024-11-16 00:53:03.946531
INFO Restoring states from the checkpoint path at rank_zero.py:63/home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/notebooks/coding_projects/P2_SVM/.lr_find_eeb25b7b-6568-46de-b7da-ccdf5af0b22b.ckpt
INFO: Restored all states from the checkpoint at /home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/notebooks/coding_projects/P2_SVM/.lr_find_eeb25b7b-6568-46de-b7da-ccdf5af0b22b.ckpt
Sat 2024-11-16 00:53:03.962106
INFO Restored all states from the checkpoint at rank_zero.py:63/home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/notebooks/coding_projects/P2_SVM/.lr_find_eeb25b7b-6568-46de-b7da-ccdf5af0b22b.ckpt
INFO: Trainer will use only 1 of 8 GPUs because it is running inside an interactive / notebook environment. You may try to set `Trainer(devices=8)` but please note that multi-GPU inside interactive / notebook environments is considered experimental and unstable. Your mileage may vary.
Sat 2024-11-16 00:54:03.800328
INFO Trainer will use only 1 of 8 GPUs because it is running inside an interactive / notebook rank_zero.py:63
environment. You may try to set `Trainer(devices=8)` but please note that multi-GPU inside
interactive / notebook environments is considered experimental and unstable. Your mileage
may vary.
INFO: GPU available: True (cuda), used: True
Sat 2024-11-16 00:54:03.836096
INFO GPU available: True(cuda), used: Truerank_zero.py:63
INFO: TPU available: False, using: 0 TPU cores
Sat 2024-11-16 00:54:03.852469
INFO TPU available: False, using: 0 TPU cores rank_zero.py:63
INFO: HPU available: False, using: 0 HPUs
Sat 2024-11-16 00:54:03.868754
INFO HPU available: False, using: 0 HPUs rank_zero.py:63
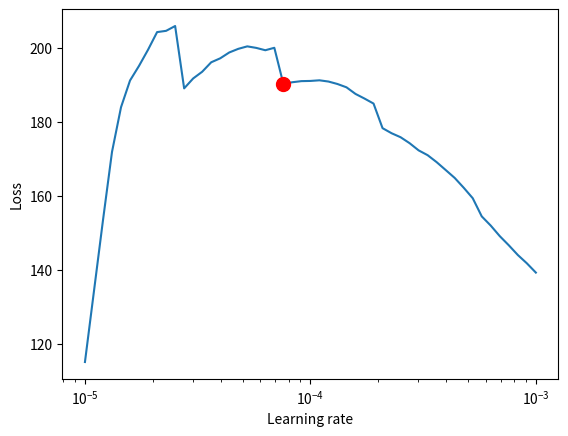
INFO `Trainer.fit` stopped: `max_steps=50` reached. rank_zero.py:63
INFO: Learning rate set to 7.585775750291839e-05
Sat 2024-11-16 00:54:11.865877
INFO Learning rate set to 7.585775750291839e-05lr_finder.py:301
INFO: Restoring states from the checkpoint path at /home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/notebooks/coding_projects/P2_SVM/.lr_find_c0a44246-c85b-407a-8dae-440075c5ae1a.ckpt
Sat 2024-11-16 00:54:11.877609
INFO Restoring states from the checkpoint path at rank_zero.py:63/home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/notebooks/coding_projects/P2_SVM/.lr_find_c0a44246-c85b-407a-8dae-440075c5ae1a.ckpt
INFO: Restored all states from the checkpoint at /home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/notebooks/coding_projects/P2_SVM/.lr_find_c0a44246-c85b-407a-8dae-440075c5ae1a.ckpt
Sat 2024-11-16 00:54:11.900391
INFO Restored all states from the checkpoint at rank_zero.py:63/home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/notebooks/coding_projects/P2_SVM/.lr_find_c0a44246-c85b-407a-8dae-440075c5ae1a.ckpt
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/fabric/plugins/environments/slurm.py:204: The `srun` command is available on your system but is not used. HINT: If your intention is to run Lightning on SLURM, prepend your python command with `srun` like so: srun python /home/ye_canming/program_files/managers/conda/envs/y ...
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/pytorch/callbacks/model_checkpoint.py:654: Checkpoint directory /home/ye_canming/repos/assignments/THU-Coursework-Machine-Learning-for-Big-Data/runs/lightning_logs/version_16/checkpoints exists and is not empty.
INFO: LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]
Sat 2024-11-16 00:58:01.204967
INFO LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]cuda.py:61
INFO:
| Name | Type | Params | Mode | In sizes | Out sizes
-------------------------------------------------------------------------------
0 | model | Linear | 650 | train | [1, 64] | [1, 10]
1 | loss_fn | MultiClassHingeLoss | 0 | train | ? | ?
-------------------------------------------------------------------------------
650 Trainable params
0 Non-trainable params
650 Total params
0.003 Total estimated model params size (MB)
2 Modules in train mode
0 Modules in eval mode
Sat 2024-11-16 00:58:01.224387
INFO model_summary.py:104
| Name | Type | Params | Mode | In sizes | Out sizes
------------------------------------------------------------------------------- 0 | model | Linear | 650 | train | [1, 64] | [1, 10]1 | loss_fn | MultiClassHingeLoss | 0 | train | ? | ?
------------------------------------------------------------------------------- 650 Trainable params 0 Non-trainable params 650 Total params 0.003 Total estimated model params size (MB)2 Modules in train mode 0 Modules in eval mode
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py:298: The number of training batches (11) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/fabric/plugins/environments/slurm.py:204: The `srun` command is available on your system but is not used. HINT: If your intention is to run Lightning on SLURM, prepend your python command with `srun` like so: srun python /home/ye_canming/program_files/managers/conda/envs/y ...
INFO: LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]
Sat 2024-11-16 00:58:03.645924
INFO LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]cuda.py:61
/home/ye_canming/program_files/managers/conda/envs/yuequ/lib/python3.10/site-packages/lightning/fabric/plugins/environments/slurm.py:204: The `srun` command is available on your system but is not used. HINT: If your intention is to run Lightning on SLURM, prepend your python command with `srun` like so: srun python /home/ye_canming/program_files/managers/conda/envs/y ...
INFO: LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]
Sat 2024-11-16 00:58:04.947243
INFO LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3,4,5,6,7]cuda.py:61